阿摩線上測驗
登入
首頁
>
教甄◆資訊科
> 114年 - 114-1 臺北市立建國高級中學_正式教師甄選試題:資訊科技科#126294
114年 - 114-1 臺北市立建國高級中學_正式教師甄選試題:資訊科技科#126294
科目:
教甄◆資訊科 |
年份:
114年 |
選擇題數:
15 |
申論題數:
18
試卷資訊
所屬科目:
教甄◆資訊科
選擇題 (15)
1. 假設有五個程序 P1, P2, P3, P4, P5 的優先權(1 比 5 優先)及所需計算時間(秒)如右表;作業系統(單 CPU)使用優先權排程演算法,試問這五個程序的平均等待時間(秒)?
(A) 2.3 (B) 3.4 (C) 4.5 (D) 5.6
(E) 6.8
2. 請計算下列後序表示法(Postfix)正確答案為何?
後序表示法(Postfix): 8 3 4 + * 10 7 2 - * -
(A) -130 (B) 130 (C) 6 (D) 38 (E) 124
3. 下列有關 IPv4 及 IPv6 的差異敘述,何者「有誤」?
(A) IP 位址的長度,IPv4 是 32 位元,IPv6 是 128 位元
(B) 和 IPv4 相同,IPv6 的 IP 表頭(Header)中亦有 Checksum 欄位
(C) 不同於 IPv4,IPv6 內建加密機制,具有更好的安全與保密性
(D) 兩者 IP 表頭(Header)中,IPv4 之欄位 Time to Live 與 IPv6 之欄位 Hop Limit 意義相同
4. 使用圖片訓練機器學習模型,將所有圖片分成不同資料集,其中專門用於檢測模型對沒遇過圖片
的表現,為以下何者?
(A) 訓練集(training dataset) (B) 驗證集(validation dataset)
(C) 測試集(test dataset) (D) 子資料集(sub dataset)
5. 以下哪個指令可以條列出區域網路內多台主機的 IP 與 MAC 的對應?
(A) nslookup (B) netstat (C) arp (D) tracert
6. 以下哪種技術是生成式人工智慧中常用的技術,請選出最適合的答案?
(A) 支持向量機(Support Vector Machine)
(B) Transformer 模型
(C) 隨機森林(Random Forest)
(D) 決策樹(Decision Tree)
7. 以下何者屬於非監督式學習?
(A) K-means 分群
(B) 線性迴歸(Linear Regression)
(C) 決策樹(Decision Tree)
(D) 支持向量機(Support Vector Machine)
8. 使用堆疊(stack)資料結構,已知 A、B、C、D、E、F 以此順序依序存入堆疊,則下列何者「不
可能」為這六個元素離開堆疊的順序?
(A) A、B、C、D、E、F
(B) A、E、F、D、B、C
(C) D、F、E、C、B、A
(D) F、E、D、C、B、A
9. 以下為一個含六個節點的圖,在圖上任選一點進行深度優先搜尋(DFS),「不可能」產生下列哪一種走訪順序?
(A) AECDBF (B) FAEDCB (C) ECBADF (D) AEFCDB
1. 當一台電腦透過瀏覽器造訪 Google (https://www.google.com/) 網站時,該電腦可能會引發哪些通
訊協定?
(A) DNS (B) TCP/IP (C) HTTP/HTTPS (D) SMTP (E) FTP
2. 以下哪種排序演算法在所有情況下都能保證 O(n log n) 的時間複雜度?
(A) 快速排序(Quick Sort)
(B) 堆積排序(Heap Sort)
(C) 合併排序(Merge Sort)
(D) 插入排序(Insertion Sort)
3. 在圖論中,以下有關 Kruskal 演算法與 Prim 演算法的說明哪些是正確的?
(A) Kruskal 以邊為基礎選擇,Prim 以頂點為基礎選擇
(B) Kruskal 使用貪婪法,Prim 使用動態規劃
(C) Kruskal 適合稀疏圖,Prim 適合稠密圖
(D) 都是用來處理最大生成樹
4. 下列有關網路的說明,哪些是正確的?
(A) 在 TCP 連線終止過程中,最後一個封包是 ACK
(B) 在計算機網路中,ICMP 協定主要負責 IP 封包的尋址與轉送
(C) TCP 協議提供二次握手特性以實現可靠數據傳輸
(D) UDP 適用於實時性要求高的場景,如視頻直播和在線遊戲
5. 以下有關資料科學的說明,哪些是正確的?
(A) Spark 使用磁碟進行數據存取, Hadoop 主要使用記憶體
(B) 關聯式數據庫適用於高度結構化型應用
(C) PCA 可以用來降維,是因為找到數據的主要變異方向,投影到較少的維度來保留主要資訊,
降低計算成本
(D)大數據分析,最常用的資料清洗技術包括刪除異常值和標準化
6. 以下敘述何者正確?
(A) 在記憶體層級架構,如:DRAM、SRAM、SSD、HDD 中,DRAM 的存儲裝置具有最快的存取速
度
(B) IPv6 使用 256 位元的位址
(C) 在資料結構中,堆疊(Stack)結構最適合用來實作遞迴演算法
(D)在人工智慧領域,非監督式學習不需要人工標註的訓練數據
申論題 (18)
第三大題:填充題
1. 請觀察下方程式碼:
請問最後印出的 a 值為何?__________。
2. 下圖 A 代表兩個「樹」的「森林」,利用左子右弟(Left-Child Right-Sibling)方法,可將森林轉
換為圖 B 的二元樹,則(1)、(2)、(3)、(4)、(5)分別代表________________。
3. A[m][n]為二維陣列,假設 A 陣列以列為主(Row Major)排列,每個元素佔用一個記憶體位
址,A[3][3]在記憶體中的位址為 121,A[6][4]在記憶體中的位址為 161,則 A[1][1]在記憶
體中的位址為何?________________。
4. 下圖中的最小生成樹(Minimum spanning tree)的成本為____________。
5. 若 F = A⊕B,⊕為 XOR 運算
當 A = 11011001,B = 01100001 時,F 之結果為何:_____________。
6. 執行以下 C++程式輸出結果為何?_____________。
7. 執行以下 C++程式輸出結果為何?_____________。
8. 機器學習模型對於訓練資料有很好的預測結果,但對於測試資料預測結果不佳,
稱作_____________。
9. 有一個二元樹(binary tree),其後序走訪(post-order traversal)為 AFECGDB,中序走訪(inorder traversal)為 AEFCBGD,請問此二元樹的前序走訪(pre-order traversal)結果為何?
_____________。
10. 資料結構的優先佇列(Priority Queue)通常使用哪一種資料結構進行實作?_____________。
11. 生成式人工智慧的生成對抗網絡(GAN)由哪兩部分組成?_____________、_____________。
12. 下面的程式碼計算兩個陣列的交集(共有元素的數量),假設兩個陣列各自都沒有重複的元素。
它計算交集的方法是對一個陣列(陣列 b)進行排序,然後迭代陣列 a 檢查每個值是否出現在陣
列 b 中(透過二元搜尋)。請問它的執行時間是多少(時間複雜度)?_______________。
13. PageRank 演算法在搜尋引擎中的作用是什麼?____________________。
四、一個無向圖 G,其頂點集為 { a, b, c, d, e },其鄰接矩陣如下表
根據其鄰接矩陣,請問從頂點 a 出發:
(a) 利用深度優先搜尋 DFS(Depth First Search)方法,走訪的順序為何?(2 分)
(b) 利用廣度優先走訪 BFS(Breadth First Search)方法,走訪的順序為何?(2 分)
(c) 請畫出無向圖 G。(1 分)
五、何謂過度擬合(Overfitting)?可能是甚麼原因造成?如何解決?
六、假設想要分析 YouBike 在哪一個時間點哪一個站點,會出現無車可借或無位可還,以此結果事先進行
車輛調度,減少此狀況。如果你是資料科學家,完成此分析的工作流程為何?
相關試卷
115年 - [無官方正解]115 臺北市立松山高級工農職業學校_正式教師甄選試題:資訊科#138619
115年 · #138619
114年 - 114 新北市國小暨幼兒園教師甄選試題:資訊科#127131
114年 · #127131
114年 - 114-2 臺北市立和平高中_教師甄試試題﹕資訊科#127057
114年 · #127057
114年 - 114 國立中科實驗高級中學_教師甄試試題_國小部:國小資訊專長#126465
114年 · #126465
114年 - 114 臺北市立麗山高級中學_正式教師甄選試題:資訊科#126462
114年 · #126462
114年 - 114-1 國立屏科實驗高級中等學校_專任教師甄選初試試題_高中部:資訊科技科#126399
114年 · #126399
114年 - 114-1 臺北市立中山女子高級中_教師甄試初選筆試試題:資訊科技科#126293
114年 · #126293
112年 - 112 國立馬祖高級中學_新進教師甄選:資訊科技及資料處理專業科目#115936
112年 · #115936
112年 - 112 連江縣國民中小學暨幼兒園新進教師聯合甄選題目試卷:國中資訊科技#115847
112年 · #115847
112年 - 112 嘉義市立大業實驗國民中學教師甄選:資訊科#115142
112年 · #115142
 阿摩線上測驗
登入
阿摩線上測驗
登入
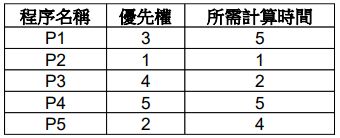 (A) 2.3 (B) 3.4 (C) 4.5 (D) 5.6
(A) 2.3 (B) 3.4 (C) 4.5 (D) 5.6 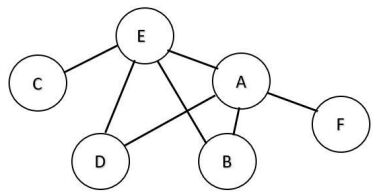 (A) AECDBF (B) FAEDCB (C) ECBADF (D) AEFCDB
(A) AECDBF (B) FAEDCB (C) ECBADF (D) AEFCDB