所屬科目:iPAS◆AI應用規劃師◆初級
1. 下列哪一個不是常見的類神經網路?(A) KNN(B) ANN(C) RNN(D) CNN
2. 下列哪一個作業不屬於圖像識別的預處理程序?(A) 放大縮小(B) 增加雜訊(C) 旋轉(D) 翻轉
3. 人的耳朵能夠聽到的聲音的基本頻率介於(A) 10Hz~10kHz(B) 20Hz~20kHz(C) 30Hz~30kHz(D) 40Hz~40kHz
4.KNN 的 K 是什麼意思?(A) K 個鄰居(B) K 個群體(C) K 是百分比(D) K 次運算
5.通常 CNN 結構不包含?(A) 卷積層(B) 池化層(C) 全連結層(D) 遞歸層
6. 黑白圖像用灰階代表灰度,黑色的值是?(A) 0(B) 100(C) 200(D) 255
7. 如果一個彩色圖像的某個像素的(R, G, B)=(255, 0, 0),則該像素是什麼顏色?(A) 紅色(B) 綠色(C) 藍色(D) 白色
8. 卷積層不是使用下列何者與原圖做卷積運算?(A) 濾波器(filter)(B) 遮罩(mask)(C) 核心(kernel)(D) 池化(pool)
9. 激活層的主要目的在於引進什麼到神經網路中?(A) 線性的因素(B) 非線性的因素(C) 特徵圖(D) 準確性
10. 在人工智慧學習時,會將收集的資料分成哪幾個部分?(A) 訓練集、驗證集(B) 訓練集、測試集(C) 測試集、驗證集(D) 訓練集、測試集、驗證集
11. 監督式學習分類的結果稱為?(A) 特徵(B) 答案(C) 標籤(D) 範圍
12. 使用電腦錄音時,下列哪一項不是需要指定的參數(A) 位元解析度(B) 頻率(C) 取樣率(D) 聲道數
13. 下列哪一個是用 AI 解決問題的步驟:(1)把問題化成函數的形式,(2)打造一個函數學習機,(3)學習,(4)收集歷史資料,(5)問一個問題。 (A) (1)(2)(3)(4)(5) (B) (5)(1)(4)(2)(3) (C) (5)(1)(3)(2)(4) (D) (1)(4)(2)(3)(5)
14. 下列哪一項是平均濾波器的效用?(A)減少雜訊(B) 凸顯特徵(C) 把圖縮小(D)邊緣偵測
15. 下列哪一項不是池化層的作用?(A)放大卷積層輸出的特徵圖(B) 壓縮卷積層輸出的特徵圖(C) 找出局部的特殊值(D)降低計算的複雜度
16. sigmoid 函數的輸出範圍?(A) 0~1(B) -1~+1(C) 0~無窮大(D) -1~0
17. 在「語音識別」的聽寫應用中,包含哪些模型?(A)聲學模型及語言模型(B) 聲學模型及音學模型(C) 音學模型及語言模型(D)聲學模型、語言模型及音學模型
18. 下列有關「動作估計(motion estimation)」的敘述,何者錯誤?(A)是提取視頻中重要資訊最常使用的方法(B) 目的在估測視頻中像素隨著時間推移在空間中的位置變化(C) 可用於視頻壓縮(video compression)(D)可用於視頻識別
19. 在圖像識別中,「資料增強(data augmentation)」增加資料量的方式?(A)只有改變亮度及改變色溫二種方式(B) 只有翻轉及縮放二種方式(C) 只有改變亮度及翻轉、縮放三種方式(D)改變亮度、翻轉、縮放及改變色溫均可
20. 神經網路學習時,會改變神經網路內的?(A)輸入值(B) 結構(C) 權重(weight)與偏值(bias)(D)激活函數
21. 令我們的卷積核(或稱遮罩)是個3✖3的大小,而圖片是個4✖4的大小,且 stride 為 1,沒有做 padding。那做完卷積運算後,得到的「結果矩陣」的大小為何?(A)3✖3(B)4✖4(C)3✖4(D)2✖2
22. 關於卷積神經網路,還有深度神經網路(deep neural network)的說明,何者錯誤? (A) 兩者都可以透過訓練的過程提升辨識的準確率 (B) 神經元相同個數的卷積神經網路通常表現的會比深度神經網路來得出色,大幅降低了訓練需要的參數量。 (C) 卷積神經網路中,一個神經元會與它上下層的每一個神經元連結。 (D) 在訓練神經網路時,其實就是在調整神經元連線上的權重參數。
23. 下列何者是 CD 的取樣率?(A) 44.1kHz(B) 44.1Hz(C) 44.1mHz(D) 44.1nHz
24. 給定兩個集合 A 和 B。集合 A 包含元素 {1, 2, 3, 4},集合 B 包含元素 {3, 4, 5, 6}。請問兩個集合的雅卡爾係數為何?(A) 0.5(B) 0.33(C) 0.67(D) 0.25
25. 關於決策樹的描述,何者有誤?(A) 決策樹是一種解釋力很強的分類模型(B) 決策樹的葉節點代表預測的類別(C) 所謂的樹的剪枝,指的是找到包含雜訊的分叉路徑,並將該路徑刪除(D) 決策樹在建構時,是由下往上遞迴地建構
26. 關於 k-means 方法,何者是錯的?(A) 它是一種非監督式學習的方法(B) 它是一種聚類方法(C) 它希望群內的差異,越大越好(D) 它希望群間差異,越大越好
27. 生成模型的中心思想是?(A) 對抗式學習(B) 非監督式學習(C) 聯邦學習(D) 對比學習
28. 對於生成對抗網路,何者說明有誤?(A) 生成對抗網路可以用來產生以假亂真的圖片(B) 生成對抗網路可以用深度神經網路來實作(C) 生成器 (Generator) 是生成對抗網路的一個元件(D) 在訓練生成器時,我們會固定生成網路,然後訓練生成網路
29. 關於強化學習的說明,何者有誤(A) 強化學習是一種監督式學習(B) Q-learning 是一種強化學習的方法(C) AlphaGo 是一個應用強化學習的例子(D) 在強化學習中,機器被稱為代理人(agent)
30. 關於 SVM 方法的說明中,何者是正確的?(A) SVM 只能做非線性分類(B) SVM 是一種非監督式學習(C) SVM 的分類函數稱為核函數。(D) SVM 是要找到最小的支持向量
31. 關於 k-means 以及 kNN 方法的說明,何者有誤?(A) kNN 是一種分類方法(B) k-mans 是一種聚類方法(C) kNN 的 k 一般會指定為奇數(D) k-means 是一種監督式學習
32. 關於視頻視別的相關任務,何者說明有誤? (A) 行為視別(action recognition)是要讓電腦自動地分析視頻,並判別出該視頻的行為標籤。 (B) 行為識別較圖像識別更為簡單 (C) 動作估計(motion estimation)會計算物件的動作向量(motion vector) (D) 物體追蹤(object tracking)是要找到視頻中某物體的移動軌跡
33. 關於神經網路的說明,何者有誤?(A) CNN 及 RNN 都是一種神經網路(B) CNN,標準 NN,RNN 都是由輸入層,隱藏層,以及輸出層構成(C) 深度學習,指的是神經網路中有較多的輸入層(D) 神經網路可以視為一個函數學習機
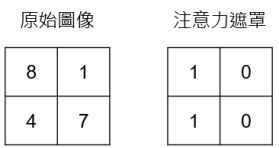
34. 底下是一張影像,以及一個注意力遮罩,請問影像通過注意力遮罩後的結果為何?(A)(B)(C)(D)
35. 關於強化學習優缺點的說明,何者有誤?(A) 強化學習適合應用在可以試誤的環境(B) 強化學習的強項就是可以跨領域學習(C) 強化學習是一種嚐試讓機器「自動學習」的方法(D) 強化學習是以心理學中行為主義理論為基礎
36. 關於迴歸模型的評估,以下說明何者錯誤? (A) 平均平方誤差 (MSE) 是一種評估迴歸模型效能的指標 (B) 平均絕對百分比誤差(mean absolute percentage error)可以讓我們「解釋」迴歸模型的誤差 (C) 平均絕對誤差(MAE)以絕對值的形式來計算迴歸誤差 (D) F1 分數(F1 score)是平衡 MSE 以及 MAE 的指標
37. 關於精確率(precision)以及召回率(recall)的說明,何者有誤?(A) 兩者在「數據不平衡」下,無法有效評量模型的效能(B) 兩者會呈現一種權衡關係,一個高,另一個就會變低(C) 兩者皆以「正類」為核心檢視模型的預測力(D) 在居家的門禁系統中,假設符合權限的家人為正類,那我們會著重提高模型的精確率。
38. 在做資料分析時,我們會將資料分成訓練集(training set),驗證集(validation set),以及測試集(testing set),請問底下說法何者有誤? (A) 訓練集用於訓練、適配模型所使用的數據 (B) 驗證集用於調整模型的超參數 (C) 測試集用於評價模型的表現 (D) 測試集會參與模型的訓練以及適配
39. 有一個影像如下所示,請問做完 max pooling 後的結果為何?(A)(B)(C)(D)
40. 有關影片中物體追蹤的順序為何?a. 進行物體偵測, b. 計算兩影格間物體特徵距離矩陣, c. 特徵配對與物體追蹤 (A) cab (B) cba (C) acb (D) abc
41. 以下有關分群與分類的描述何者有誤?(A) 分類是將未知的新訊息歸納進已知的資訊中(B) 分群屬於監督式學習,而分類屬於非監督式學習(C) 分類的結果稱為標籤(label)(D) 分群是透過資料所具有的特徵區分類別或群體
42. 下列有關神經網路的敘述何者有誤?(A) 標準神經網路又稱為全連結神經網路(B) 不同神經網路的架構可以混用,建構出功能不同的學習機器(C) 隱藏層達到十層以上才符合深度學習的標準(D) 神經網路由輸入層、隱藏層及輸出層組成
43. 下列何者不在生成對抗網路的架構中?(A) 判別器(B) 生成器(C) 對抗器(D) 真實內容/生成內容
44. YouTube 的自動字幕產生系統屬於哪種語音識別系統?(A) 對話(B) 關鍵詞偵測(C) 聽寫(D) 語音命令
45. 下列何者關於「K 最近鄰居法」與「K-平均演算法」的描述有誤?(A) 兩者均屬分類演算法(B) 「K-平均演算法」需計算某些樣本點的重心(C) 「K 最近鄰居法」的 k 值設定一般以奇數為原則(D) 兩者皆須計算樣本點間的距離
46. 一個 frame per second (fps)為 30 的影片,總長度為 5 分鐘,其資料量為單張圖像的幾倍?(A) 150(B) 300(C) 1800(D) 9000
47. 若依難度區分語音識別系統,下列何者難度較高?(A) 關鍵詞偵測(keyword spotting)(B) 語音命令(voice command)(C) 對話(dialog)(D) 聽寫(dictation)
48. 假設有以下書籍銷售紀錄,關聯規則 B→C 的信賴度(confidence)為何? (A) 75% (B) 85% (C) 95% (D) 100%
49. 下列關於音訊的基本聲學特徵何者有誤?(A) 在分析音訊時須先將音訊切成比較短的音框(B) 每秒出現的音框數稱為音框率,音框率越高所需的計算資源越少(C) 一個音框須包含數個基本週期才能充分擷取音訊的特徵(D) 音量、音高及音色等為聲學特徵的一種
50. 若以「K 最近鄰居法」將右圖中資料點分群的話,k 設為多少可將*歸類在 O?(A) 9(B) 7(C) 5(D) 3
 阿摩線上測驗
登入
阿摩線上測驗
登入
 (A)
(A)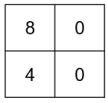 (B)
(B)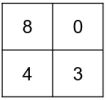 (C)
(C)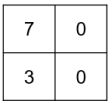 (D)
(D)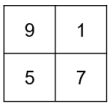
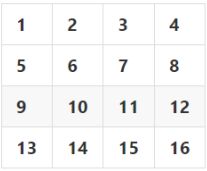 (A)
(A) (B)
(B)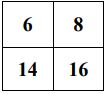 (C)
(C)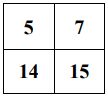 (D)
(D)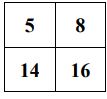
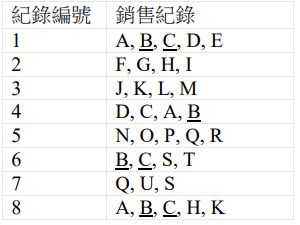 (A) 75% (B) 85% (C) 95% (D) 100%
(A) 75% (B) 85% (C) 95% (D) 100%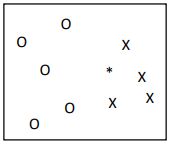 (A) 9(B) 7(C) 5(D) 3
(A) 9(B) 7(C) 5(D) 3